 |
| EPI9-2: THE QUALITY OF MEASUREMENTS: The Broad Meaning Of Validity |
|
| EPI9-2: THE QUALITY OF MEASUREMENTS: The Broad Meaning Of Validity |
OBJECTIVES |
At the end of this session you should know the theree different levels of meaning of the Validity:
|
The term validity is commonly used loosely to mean different things. At least three different usages are found:
As pertaining to a study as a whole: Internal validity refers to the validity of the inferences as they pertain to the study population and has to do with the internal workings of the research process. External validity is a global judgement based on a thorough critique of the study according to a checklist resulting in a judgement about the overall validity of the findings. (Refer: Long checklist for critical appraisal). It refers to the validity of findings with respect to people outside the study population, and is often a question of informed judgement rather than scientific calculation. It is striking the extent to which so much of this aspect of epidemiology is a matter of subjective interpretation of prior as well as knowledge gained from the study in question. This is the "art" aspect of epidemiology. Rothman has an interesting discussion of external validity and the inferential process in terms of the conceptual superpopulation and the extraction of abstract principles and relationships. There is also a useful discussion of the role of subject entry restriction in strengthening study design for causal inference despite loss of representativeness.
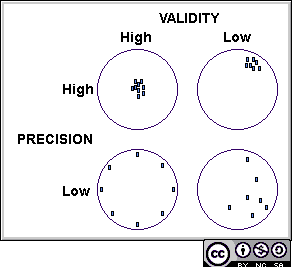 More narrowly pertaining to an individual measurement. This is the illustrated win the target diagram on the right. Please note that the measure could be that of an occurrence or an effect. Here validity is defined as the extent to which a measurement measures what it intends to measure and not something else. The concept of validity reflects how "true" the measurement is. The Target diagram also illustrates the distinct concepts of precision and validity.
More narrowly pertaining to an individual measurement. This is the illustrated win the target diagram on the right. Please note that the measure could be that of an occurrence or an effect. Here validity is defined as the extent to which a measurement measures what it intends to measure and not something else. The concept of validity reflects how "true" the measurement is. The Target diagram also illustrates the distinct concepts of precision and validity.
The "truth" is known due to the existence of a gold standard for measurement. The measure used is strongly associated with a criterion for "truth". For example, the results from urine tests for glucose are validated against a criterion supplied by the Glucose Tolerance Test.
The performance of the urine screening test is expressed as its sensitivity, specificity, positive and negative predictive values.
Test results are associated with subsequent events as they develop over time. For example, the smoking status at the time of a pre-employment examination is a valid predictor or the development of chronic respiratory disease over many years.
A set of test results is known to be associated with a variable. Theoretically, these test results can also be hypothesised to be associated with another related variable. For example, alcohol consumption is known to be associated with a neuropsychological test result - that is, the test is valid for detecting this association. This suggests that the test should also be valid for detecting an association with workplace organic solvent exposure, since alcohol is a closely related chemical substance.
Two sets of results from two different tests are correlated with each other and both test a construct, for example, IQ when applied to the same population. The construct of IQ (as measured by both tests) is thus validated.
Test results seem to make obvious sense or nonsense in terms of a priori expectations. For example, the prevalence of diabetes in a community based study is 0%, 3% or 24%. On the face of it the middle one is correct, the others are not.
Does the content of the test (usually a questionnaire in this instance) cover the "truth" that is being estimated? For example, a questionnaire asking about paranoia - "Do you feel people are watching you?" - measures something different depending upon the culture of the person answering.
Is there consensus among "experts" as to the validity of the measure? For example, when two experienced radiologists agree that pneumoconiosis is present among 10% of the workforce.
![]()
![]()
![]()
